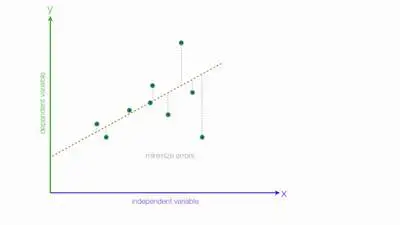
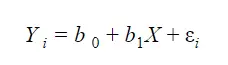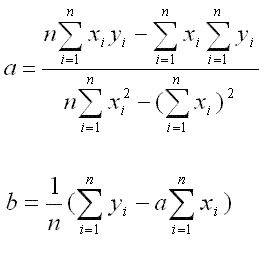When you are conducting a study, there’s nothing better than having all your data nice and straight. After all, you know that when this happens, it is easier to predict outcomes. However, this doesn’t always happen.
Discover the best online statistics calculators.
The reality is that sometimes, you want to know how likely something happens and not the actual outcome. So, you need to look at logistic regression.
What is Logistic Regression?
As you probably remember, variables can be either categorical or continuous. Categorical variables are the ones that exist as some sort of discrete unit like multiple choice answers. On the other hand, continuous variables are the ones that exist on some scale like gas mileage or height.
As you can easily understand, each type of variable has a particular type of statistics linked with them due to their nature.
Understanding the difference between correlation and linear regression.
In the case of linear regression, you deal with continuous variables. This way, you can analyze the data and predict an outcome based on a scale. However, in what concerns to categorical variables, there are no traditional scales or lines. So, this means you can’t use linear regression.
So, when this happens, the first thing you need to look at is binary logistic regression. Let’s take a look at a more practical example. Imagine that you just asked some people if they think the temperature (in Fahrenheit) is too hot. Their answers are expressed in the chart below:
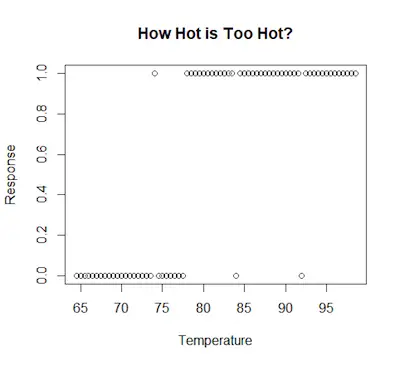
As you can see, the data isn’t a normal scatter plot. You can see that the data points aren’t all over the place – they are focused on either 1 or 0 because these were the answers people have to choose from.
Discover how to perform a simple regression analysis.
This means you can’t calculate the typical line as you would for linear regression because there is no “sort of” response.
Instead, you need to calculate the probability of a person responding either 1 or 0. That is what binary logistic regression is for. We use it to calculate the chance of a person responding to one of two choices.
The general model for binary logistic regression is:
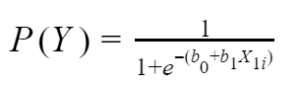
Where:
- P(Y) means that we are calculating the probability of an outcome of 1 occurring.
- e shows the use of logarithmic functions that create a line of best fit for the data.
So, after running the analysis, your model looks like this:
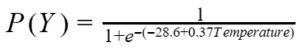
Is Your Model Any Good?
One of the things that you always need to keep in mind about logistic regression is that this type of model can’t be interpreted as a linear regression model using R2.
The truth is that with the logistic regression, you are interested in the probability of an outcome and not in the actual outcome. Therefore, you need to consider the likelihood of an outcome. This is called log-likelihood.
Learn how to interpret regression coefficients.
Simply put, the log-likelihood refers to adding the probability of the predicted outcome to the probability of the actual outcome so that you can get a sense of how well our model explains all the probability of the event occurring.